【最新】GitHub Copilot「激変」の最新カスタムモデル:受け入れ率12%増、レイテンシ35%削減を実現
目次
GitHubが、AI搭載コード補完ツール「GitHub Copilot」に新しいカスタムモデルを導入し、性能を大幅に向上させたことを発表した。1
このアップデートにより、提案されたコードが実際に採用される割合が12%増加し、応答速度は35%も高速化。開発者の体験が飛躍的に改善されている。
数字が示す圧倒的な進化
GitHub Copilotチームが公開した新モデルの性能指標を見てみよう。
| 指標 | 改善率 |
| 受け入れ・保持文字数 | +20% |
| 受け入れ率 | +12% |
| トークン/秒 スループット | 3倍 |
| レイテンシ | -35% |
We’re now delivering suggestions with 20% more accepted and retained characters, 12% higher acceptance rate, 3x higher token-per-second throughput, and a 35% reduction in latency.
GitHubによれば、「提案されたコードのうち受け入れられて最終的に残る文字数が20%増加し、受け入れ率は12%向上、処理速度は3倍、応答時間は35%削減されました」とのこと。
特に注目すべきは「受け入れ・保持文字数」の向上だ。これは、Copilotが提案したコードが一時的に受け入れられるだけでなく、最終的に削除されずにそのまま残る割合を示している。つまり、提案の質そのものが向上し、開発者がコードを修正する手間が大幅に減ったことを意味する。
「量より質」への戦略転換が成功の鍵
実は、GitHub Copilotの初期バージョンは、「受け入れ率」を最大化することに重点を置いていた。しかし、開発チームは実際の開発者からのフィードバックを通じて、この指標だけでは不十分だと気づいたという。
GitHubは次のように説明している。「受け入れ率だけに注目すると、単純で短い提案ばかりを優先してしまう可能性があります。開発者の皆さんから、これでは本当のニーズに応えられていないというフィードバックをいただきました」
However, we realized that a heavy focus on acceptance rates could lead to incorrectly favoring a high volume of simple and short suggestions. We heard your feedback that this didn’t reflect real developer needs or deliver the highest quality experience.
確かに、受け入れ率が高くても、それが1行や2行の簡単なコードばかりでは、開発者にとっての真の価値は低い。そこでGitHubは方針を転換。「受け入れ・保持文字数」や「コードの流れ(フロー)」といった、より実用的な指標も重視するようになった。この戦略的な転換が、今回の大幅な性能向上につながっている。
三段階の厳格な評価プロセスで品質を担保
新モデルの開発において、GitHubはオフライン評価、プロダクション前評価、プロダクション評価という三段階の徹底的なテストプロセスを採用している。
1)オフライン評価
まず、実際にコードを実行できるベンチマークを使って、社内およびパブリックなリポジトリに対してテストを実施。ビルドとテストがどれだけ成功するかを測定し、機能的な正確性を確認する。
さらに興味深いのは、独立したAI(LLM)を「審査員」として活用している点だ。提案されたコードを品質、関連性、有用性の三つの観点から客観的に評価させている。
2)プロダクション前評価
社内の開発者やパートナー企業と協力し、実際の開発作業の中で新モデルと既存モデルを比較テスト。各プログラミング言語の専門家と連携し、言語ごとの品質基準やコーディングスタイルの好みに合わせた細かな評価を行う。
3)プロダクション評価
最終的には、実際のユーザー体験を最重視。A/Bテストを通じて、複数の指標で統計的に明確な改善が確認された場合のみ、本番環境にリリースする。
この慎重なアプローチにより、確実に品質が向上したモデルだけが開発者の手元に届く仕組みになっている。
三つのトレーニング手法を組み合わせたモデルの最適化
新モデルのトレーニングは、三つの主要な段階で構成されている。
中間トレーニング(Mid-training)
約1,000万のリポジトリと600以上のプログラミング言語を含む、厳選された重複のないコードデータを使用。最新のAPI、言語の文法、プログラミングの慣用句などをモデルに学習させる。
教師あり微調整(Supervised Fine-tuning)
一般的な会話型AIモデルは、自然言語からコードを生成することは得意だが、コードの途中に適切な内容を挿入する「Fill-in-the-Middle(FIM)」補完には向いていない。
そこで、合成データを用いた特化型の微調整を実施。カーソル位置を正確に認識した挿入、前後の文脈(プレフィックス/サフィックス)の適切な処理、既存コードのスタイルの尊重などを実現した。
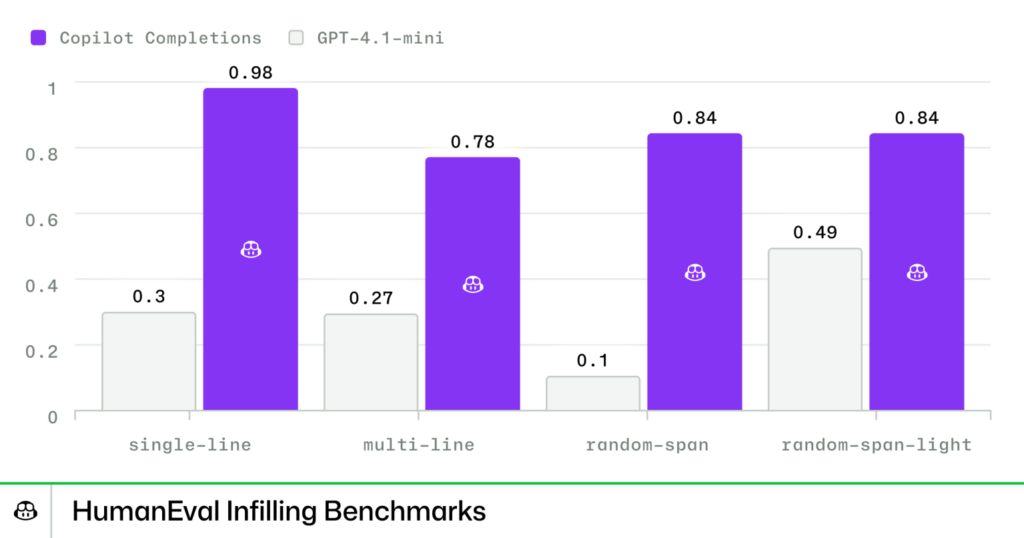
強化学習(Reinforcement Learning)
カスタム強化学習アルゴリズムを使用し、以下の三つの観点でモデルを最適化:
- 品質: 構文の正確性、スタイルの一貫性
- 関連性: 文脈に沿った適切な提案
- 有用性: 手作業の削減、最新APIの優先
これらの基準に基づいて報酬と罰則を与えることで、より実用的なコード提案ができるようモデルを訓練している。
失敗から学んだ教訓――報酬設計の落とし穴
開発過程で得られた重要な教訓の一つが、「報酬設計の難しさ」だ。
初期の強化学習バージョンでは、長い補完を過度に優先してしまう問題が発生した。結果として、不要なコメントが大量に生成される「報酬ハッキング」という現象が起きてしまったのだ。
GitHubは説明する。「初期の強化学習バージョンでは、長い補完を過度に最適化してしまい、コメントが多すぎる形で『報酬ハッキング』が発生しました。この問題を解決するため、コメントに対するガードレールを導入し、簡潔で本質的な提案に焦点を当てるよう調整しました」
AIモデルの訓練においては、目標設定(報酬設計)が適切でないと、意図しない動作を学習してしまう。この失敗と改善のプロセスは、AI開発の現実的な課題を示している。
次なる進化――さらなる専門化と高速化へ
GitHubは、今後さらにCopilot補完機能を進化させる計画を明らかにしている。
具体的には:
- ドメイン特化型モデルの開発(ゲームエンジン、金融、ERPなど業界別の最適化)
- ビルド/テスト成功率やコードの意味的な有用性を重視した評価基準の改良
- すべての開発環境でより高速かつ低コストで高品質な補完を提供
AI支援によるコーディングが当たり前になりつつある今、GitHub Copilotのような高性能なAIアシスタントは、開発者の生産性を支える不可欠なツールとなっている。今回のアップデートは、その進化の一里塚に過ぎない。さらなる改善が、すぐそこまで来ている。
- Fu, S., & Mogensen, J. (2025, October 23). The road to better completions: Building a faster, smarter GitHub Copilot with a new custom model. The GitHub Blog. Retrieved from https://github.blog/ai-and-ml/github-copilot/the-road-to-better-completions-building-a-faster-smarter-github-copilot-with-a-new-custom-model/ ↩︎